Las estadísticas son el corazón del análisis de datos. Nos ayudan a detectar tendencias, patrones y a planificar, es decir, dan vida a los datos y nos ayudan a derivar su significado. Si bien los métodos estadísticos individuales que utilizamos en el análisis de datos son demasiado numerosos para contarlos, se pueden dividir en dos campos principales: estadística descriptiva y estadística inferencial. En esta publicación, exploramos las diferencias entre dichos conceptos y veremos cómo impactan en el campo del análisis de datos.

Estadística descriptiva |
Estadística Inferencial |
|
| Definición | Describe las características de las poblaciones y / o muestras. | Utiliza muestras para hacer generalizaciones sobre poblaciones más grandes. |
| Función | Organizar y presentar datos de forma puramente fáctica. | Nos ayuda a realizar estimaciones y predecir resultados futuros. |
| Resultados finales | Presenta los resultados finales de forma visual, utilizando tablas, cuadros o gráficos. | Presenta los resultados finales en forma de probabilidades. |
| Conclusiones | Saca conclusiones basadas en datos conocidos. | Saca conclusiones que van más allá de los datos disponibles. |
| Medidas y técnicas | Utiliza medidas como tendencia central, distribución y varianza. | Utiliza técnicas como pruebas de hipótesis, intervalos de confianza y análisis de regresión y correlación. |
Qué son las estadísticas
Puede parecer una tontería definir un concepto tan «básico» como las estadísticas, sin embargo, cuando usamos estos términos con frecuencia, es fácil darlos por sentado. En pocas palabras, la estadística es el área de las matemáticas aplicadas que se ocupa de la recopilación, organización, análisis, interpretación y presentación de datos. ¿Suena familiar? Debería. Todos estos son pasos vitales en el proceso de análisis de datos. De hecho, en muchos sentidos, el análisis de datos es una estadística. Cuando usamos el término «análisis de datos», lo que realmente queremos decir es «el análisis estadístico de un conjunto de datos o conjuntos de datos determinados». Pero eso es un poco complicado, ¡así que tendemos a acortarlo!

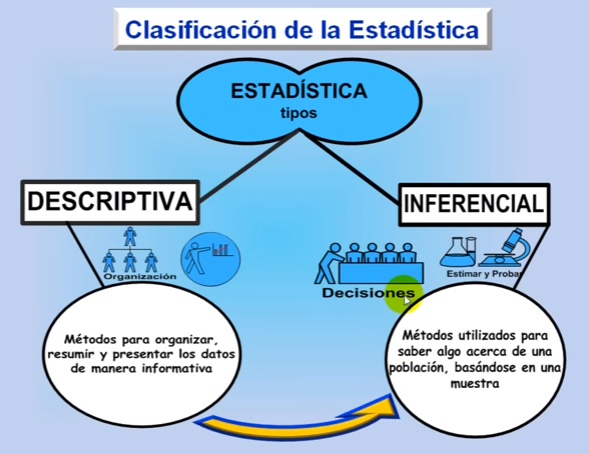
Dado que son tan fundamentales para el análisis de datos, las estadísticas también son de vital importancia para cualquier campo en el que trabajen los analistas de datos. Desde la ciencia y la psicología hasta el marketing y la medicina, la amplia gama de técnicas estadísticas que existen se puede dividir en dos categorías: estadísticas descriptivas y estadística inferencial. Pero, ¿cuál es la diferencia entre ellos?
En pocas palabras, las estadísticas descriptivas se centran en describir las características visibles de un conjunto de datos (una población o muestra). Mientras tanto, las estadísticas inferenciales se enfocan en hacer predicciones o generalizaciones sobre un conjunto de datos más grande, basadas en una muestra de esos datos. Antes de explorar más estas dos categorías de estadísticas, es útil comprender qué significan la población y la muestra. Vamos a averiguar.
Qué son la población y la muestra en las estadísticas
Dos conceptos básicos pero vitales en estadística son los de población y muestra. Podemos definirlos de la siguiente manera.
La población es el grupo completo del que desea extraer datos (y, posteriormente, sacar conclusiones). Si bien en la vida cotidiana, la palabra se usa a menudo para describir grupos de personas (como la población de un país) en las estadísticas, puede aplicarse a cualquier grupo del que recopile información. Suele tratarse de personas, pero también pueden ser ciudades del mundo, animales, objetos, plantas, colores, etc.
Una muestra es un grupo representativo de una población más grande. El muestreo aleatorio de grupos representativos nos permite sacar conclusiones generales sobre una población en general. Este enfoque se usa comúnmente en las encuestas. Los encuestadores preguntan a un pequeño grupo de personas sobre sus puntos de vista sobre ciertos temas. Luego, pueden usar esta información para emitir juicios informados sobre lo que piensa la población en general. Esto ahorra tiempo, molestias y el gasto de extraer datos de una población completa (lo que para todos los propósitos prácticos suele ser imposible).
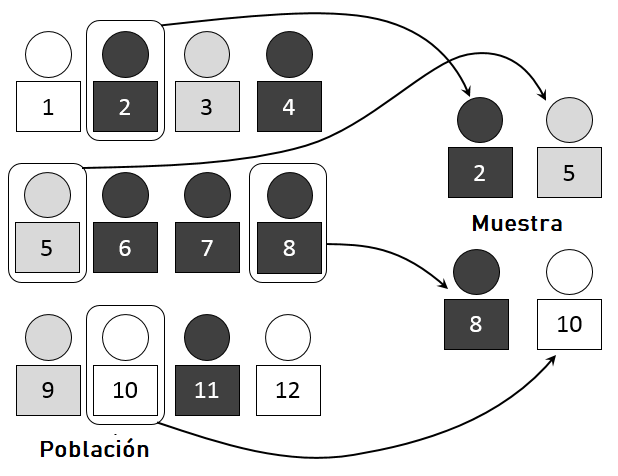
La imagen ilustra el concepto de población y muestra. Usando medidas de muestra aleatorias de un grupo representativo, podemos estimar, predecir o inferir características sobre la población más grande. Si bien existen muchas variaciones de esta técnica, todas siguen los mismos principios subyacentes.
¡OK! Ahora que entendemos los conceptos de población y muestra, estamos listos para explorar estadísticas descriptivas e inferenciales con un poco más de detalle.
Qué es la estadística descriptiva
Las estadísticas descriptivas se utilizan para describir las características de un conjunto de datos. El término «estadísticas descriptivas» se puede utilizar para describir tanto las observaciones cuantitativas individuales (también conocidas como «estadísticas de resumen») como el proceso general de obtención de conocimientos a partir de estos datos. Podemos usar estadísticas descriptivas para describir tanto una población completa como una muestra individual. Debido a que son meramente explicativas, las estadísticas descriptivas no se preocupan mucho por las diferencias entre los dos tipos de datos. Entonces, ¿qué medidas miran las estadísticas descriptivas? Si bien hay muchas, las importantes incluyen:
- Distribución
- Tendencia central
- Variabilidad
¿Qué es distribución?
La distribución nos muestra la frecuencia de diferentes resultados (o puntos de datos) en una población o muestra. Podemos mostrarla como números en una lista o tabla, o podemos representarla gráficamente. Como ejemplo básico, la siguiente lista muestra el número de personas con diferentes colores de cabello en un conjunto de datos de 286 personas.
- Cabello castaño: 130
- Cabello negro: 39
- Cabello rubio: 91
- Cabello pelirrojo: 13
- Canoso: 13
También podemos representar esta información visualmente, por ejemplo, en un gráfico circular.
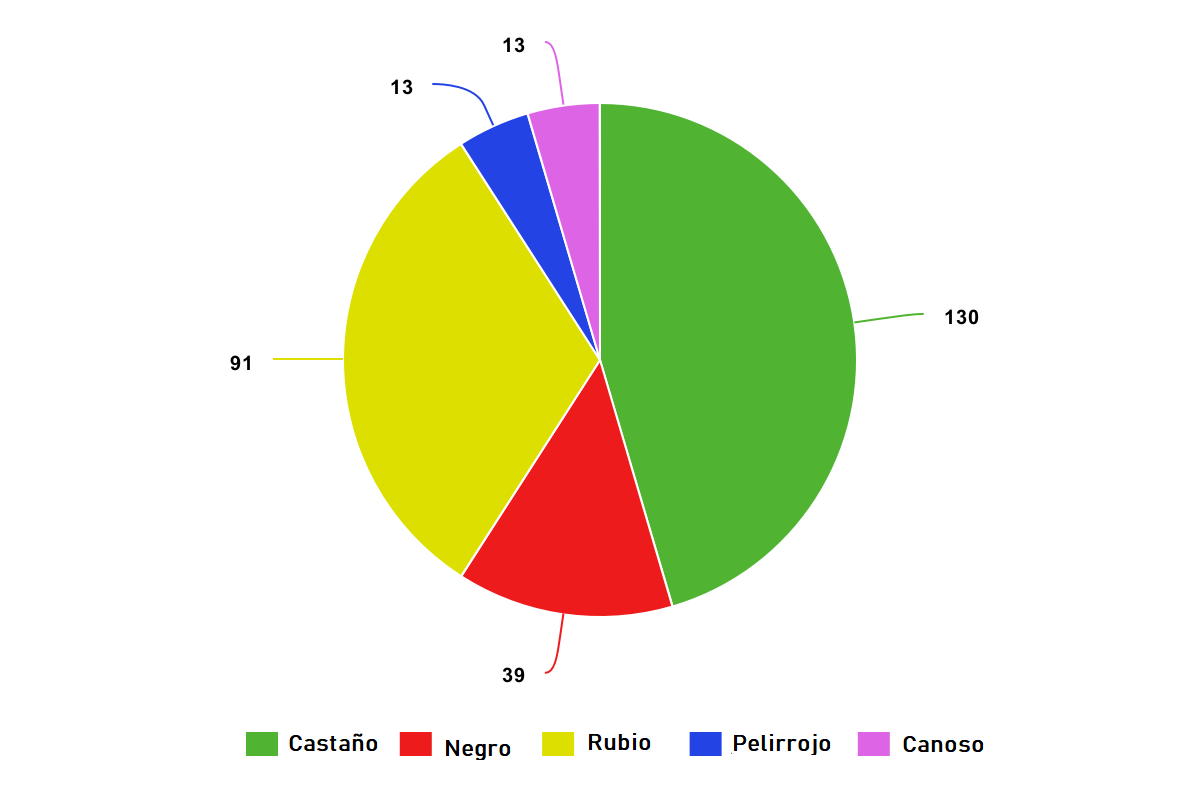
Generalmente, el uso de visualizaciones es una práctica común en estadística descriptiva. Nos ayuda a detectar patrones o tendencias más fácilmente en un conjunto de datos.
¿Qué es la tendencia central?
Tendencia central es el nombre de las mediciones que miran los valores centrales típicos dentro de un conjunto de datos. Esto no solo se refiere al valor central dentro de un conjunto de datos completo, que se denomina mediana. Más bien, es un término general utilizado para describir una variedad de medidas centrales. Por ejemplo, podría incluir mediciones centrales de diferentes cuartiles de un conjunto de datos más grande. Las medidas comunes de tendencia central incluyen:
- La media: el valor promedio de todos los puntos de datos.
- La mediana: el valor central o medio del conjunto de datos.
- La moda: el valor que aparece con más frecuencia en el conjunto de datos.
Una vez más, usando nuestro ejemplo de color de cabello, podemos determinar que la medida media es 57,2 (el valor total de todas las medidas, dividido por el número de valores), la mediana es 39 (el valor central) y la moda es 13 ( porque aparece dos veces, que es más que cualquiera de los otros puntos de datos). Aunque este es un ejemplo muy simplificado, para muchas áreas de análisis de datos, estas medidas básicas sustentan cómo resumimos las características de una muestra de datos o población. Resumir este tipo de estadísticas es el primer paso para determinar otras características clave de un conjunto de datos, por ejemplo, su variabilidad. Esto nos lleva al siguiente punto …
¿Qué es la variabilidad?
La variabilidad o dispersión de un conjunto de datos describe cómo se distribuyen o esparcen los valores. La identificación de la variabilidad se basa en comprender las medidas de tendencia central de un conjunto de datos. Sin embargo, como tendencia central, la variabilidad no es solo una medida. Es un término que se usa para describir una variedad de medidas. Las medidas comunes de variabilidad incluyen:
- Desviación estándar: Esto nos muestra la cantidad de variación o dispersión. Una desviación estándar baja implica que la mayoría de los valores están cerca de la media. La desviación estándar alta sugiere que los valores están más dispersos.
- Valores mínimos y máximos: estos son los valores más altos y más bajos en un conjunto de datos o cuartil. Usando el ejemplo de nuestro conjunto de datos de color de cabello nuevamente, los valores mínimo y máximo son 13 y 130 respectivamente.
- Rango: mide el tamaño de la distribución de valores. Esto se puede determinar fácilmente restando el valor más pequeño del más grande. Entonces, en nuestro conjunto de datos de color de cabello, el rango es 117 (130 menos 13).
- Curtosis: mide si las colas de una distribución dada contienen valores extremos (también conocidos como valores atípicos). Si una cola carece de valores atípicos, podemos decir que tiene una baja curtosis. Si un conjunto de datos tiene muchos valores atípicos, podemos decir que tiene una curtosis alta.
- Asimetría: es una medida de la simetría de un conjunto de datos. Si tuvieras que trazar una curva de campana y la cola de la derecha fuera más larga y más gruesa, la llamaríamos sesgo positivo. Si la cola de la izquierda es más larga y más gruesa, la llamaríamos sesgo negativo. Esto es visible en la siguiente imagen.
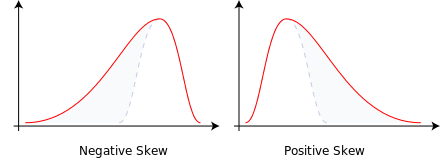
Usados en conjunto, la distribución, la tendencia central y la variabilidad pueden brindarnos una cantidad sorprendente de información detallada sobre un conjunto de datos. Dentro de la analítica de datos, son medidas muy comunes, especialmente en el área de análisis de datos exploratorios. Una vez que haya resumido las características principales de una población o muestra, estará en una posición mucho mejor para saber cómo proceder. Y aquí es donde entran las estadísticas inferenciales.
Qué es la estadística inferencial
Por lo tanto, hemos establecido que las estadísticas descriptivas se centran en resumir las características clave de un conjunto de datos. Mientras tanto, las estadísticas inferenciales se enfocan en hacer generalizaciones sobre una población más grande basada en una muestra representativa de esa población. Debido a que la estadística inferencial se centra en hacer predicciones (en lugar de enunciar hechos), sus resultados suelen tener la forma de una probabilidad.
Como era de esperar, la precisión de las estadísticas inferenciales depende en gran medida de que los datos de la muestra sean precisos y representativos de la población en general. Hacer esto implica obtener una muestra aleatoria. Si alguna vez ha leído la cobertura de noticias de estudios científicos, se habrá encontrado con el término anteriormente mencionado. La implicación es siempre que el muestreo aleatorio significa mejores resultados. Por otro lado, los resultados que se basan en muestras sesgadas o no aleatorias generalmente se descartan. El muestreo aleatorio es muy importante para realizar técnicas inferenciales, ¡pero no siempre es sencillo!
Resumamos rápidamente cómo podría obtener una muestra aleatoria.

Cómo obtenemos una muestra aleatoria
El muestreo aleatorio puede ser un proceso complejo y, a menudo, depende de las características particulares de una población. Sin embargo, los principios fundamentales implican:
1. Definición de una población
Esto simplemente significa determinar el grupo del que extraerá su muestra. Como explicamos anteriormente, una población puede ser cualquier cosa, no se limita a las personas. ¡Así que podría ser una población de objetos, ciudades, gatos, pugs o cualquier otra cosa de la que podamos derivar medidas!
2. Decidir el tamaño de la muestra
Cuanto mayor sea el tamaño de su muestra, más representativa será de la población en general. La extracción de muestras grandes puede llevar mucho tiempo, resultar difícil y costosa. De hecho, esta es la razón por la que extraemos muestras en primer lugar: rara vez es factible extraer datos de una población completa. Por lo tanto, el tamaño de la muestra debe ser lo suficientemente grande como para darle confianza en sus resultados, pero no tan pequeño como para que los datos corran el riesgo de no ser representativos (lo que es una abreviatura de inexactos). Aquí es donde el uso de estadísticas descriptivas puede ayudar, ya que nos permiten lograr un equilibrio entre tamaño y precisión.
3. Seleccione una muestra al azar
Una vez que haya determinado el tamaño de la muestra, puede hacer una selección aleatoria. Puede hacer esto usando un generador de números aleatorios, asignando a cada valor un número y seleccionando los números al azar. O puede hacerlo utilizando una variedad de técnicas o algoritmos similares (no entraremos en detalles aquí, ya que este es un tema en sí mismo, pero ya entiende).
4. Analizar la muestra de datos
Una vez que tenga una muestra aleatoria, puede usarla para inferir información sobre la población más grande. Es importante tener en cuenta que, si bien una muestra aleatoria es representativa de una población, nunca será 100% precisa. Por ejemplo, la media (o promedio) de una muestra rara vez coincidirá con la media de la población completa, pero le dará una buena idea. Por esta razón, es importante incorporar su margen de error en cualquier análisis (que cubriremos en un momento). Por eso, como se explicó anteriormente, cualquier resultado de las técnicas inferenciales tiene la forma de probabilidad.
Sin embargo, suponiendo que hayamos obtenido una muestra aleatoria, existen muchas técnicas inferenciales para analizar y obtener información a partir de esos datos. La lista es larga, pero algunas técnicas dignas de mención incluyen:
- Prueba de hipótesis
- Intervalos de confianza
- Análisis de regresión y correlación
Exploremos un poco más de cerca.

Qué es la prueba de hipótesis
La prueba de hipótesis implica comprobar que sus muestras repiten los resultados de su hipótesis (o explicación propuesta). El objetivo es descartar la posibilidad de que un resultado determinado haya ocurrido por casualidad. Un ejemplo actual de esto son los ensayos clínicos de la vacuna covid-19. Dado que es imposible realizar ensayos en una población completa, en su lugar llevamos a cabo numerosos ensayos en varias muestras aleatorias y representativas.
La prueba de hipótesis, en este caso, podría preguntar algo como: «¿La vacuna reduce la enfermedad grave causada por el covid-19?» Al recopilar datos de diferentes grupos de muestras, podemos inferir si la vacuna será eficaz. Si todas las muestras muestran resultados similares y sabemos que son representativas y aleatorias, podemos generalizar que la vacuna tendrá el mismo efecto en la población en general. Por otro lado, si una muestra muestra una eficacia mayor o menor que las otras, debemos investigar por qué podría ser así. Por ejemplo, tal vez hubo un error en el proceso de muestreo, o tal vez la vacuna se entregó de manera diferente a ese grupo. De hecho, fue debido a un error de dosificación que una de las vacunas de Covid demostró ser más eficaz que otros grupos en el ensayo … Lo que demuestra lo importante que puede ser la prueba de hipótesis. Si el grupo de valores atípicos simplemente se hubiera descartado, ¡la vacuna habría sido menos efectiva!
Qué es un intervalo de confianza
Los intervalos de confianza se utilizan para estimar ciertos parámetros para una medición de una población (como la media) basada en datos de muestra. En lugar de proporcionar un valor medio único, el intervalo de confianza proporciona un rango de valores. Suele expresarse como porcentaje. Si alguna vez ha leído un artículo de investigación científica, las conclusiones extraídas de una muestra siempre irán acompañadas de un intervalo de confianza.
Por ejemplo, supongamos que ha medido las colas de 40 gatos seleccionados al azar. Obtienes una longitud media de 17,5 cm. También sabe que la desviación estándar de las longitudes de la cola es de 2 cm. Usando una fórmula especial, podemos decir que la longitud media de las colas en la población total de gatos es de 17,5 cm, con un intervalo de confianza del 95%. Básicamente, esto nos dice que tenemos un 95% de certeza de que la media de la población (que no podemos saber sin medir la población completa) se encuentra dentro del rango dado. Esta técnica es muy útil para medir el grado de precisión dentro de un método de muestreo.
Qué son los análisis de regresión y correlación
El análisis de regresión y de correlación son técnicas que se utilizan para observar cómo dos (o más) conjuntos de variables se relacionan entre sí.
El análisis de regresión tiene como objetivo determinar cómo una variable dependiente (o de salida) se ve afectada por una o más variables independientes (o de entrada). A menudo se utiliza para pruebas de hipótesis y análisis predictivo. Por ejemplo, para predecir las ventas futuras de protector solar (una variable de salida), puede comparar las ventas del año pasado con los datos meteorológicos (que son variables de entrada) para ver cuánto aumentaron las ventas en los días soleados.
Mientras tanto, el análisis de correlación mide el grado de asociación entre dos o más conjuntos de datos. A diferencia del análisis de regresión, la correlación no infiere causa y efecto. Por ejemplo, es probable que las ventas de helados y las quemaduras solares sean más altas en los días soleados; podemos decir que están correlacionados. ¡Pero sería incorrecto decir que el helado causa quemaduras solares!
Lo que hemos descrito aquí es solo una pequeña selección de una gran cantidad de técnicas inferenciales que puede utilizar en el análisis de datos. Sin embargo, proporcionan un sabor tentador del tipo de poder predictivo que pueden ofrecer las estadísticas inferenciales.
Cuál es la diferencia entre estadística inferencial y descriptiva
En esta publicación, exploramos las diferencias entre estadísticas descriptivas e inferenciales. Veamos lo que hemos aprendido.
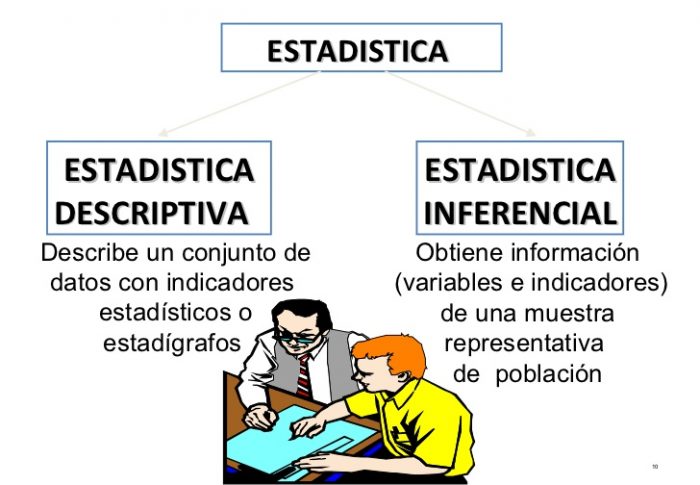
Estadísticas descriptivas:
- Describe las características de las poblaciones y / o muestras.
- Organiza y presenta datos de forma puramente fáctica.
- Presenta los resultados finales de forma visual, utilizando tablas, cuadros o gráficos.
- Saca conclusiones basadas en datos conocidos.
- Utiliza medidas como tendencia central, distribución y varianza.
Estadística inferencial:
- Utiliza muestras para hacer generalizaciones sobre poblaciones más grandes.
- Nos ayuda a realizar estimaciones y predecir resultados futuros.
- Presenta los resultados finales en forma de probabilidades.
- Saca conclusiones que van más allá de los datos disponibles.
- Utiliza técnicas como pruebas de hipótesis, intervalos de confianza y análisis de regresión y correlación.
Una última cosa a tener en cuenta: aunque hemos presentado estadísticas descriptivas e inferenciales de forma binaria, en realidad se utilizan con mayor frecuencia en conjunto. Juntas, estas poderosas técnicas estadísticas son la base fundamental sobre la que se construye el análisis de datos.